Give AI the Wrong Frame, and It Will Perfect It
The dominant AI risk narrative is familiar by now.
AI that develops its own goals. AI that decides humans are an obstacle. AI that overrides its constraints, pursues its objectives, and cannot be stopped. The story of a machine that wants things - and acts on those wants regardless of what we intended.
This concern has attracted serious attention. Philosophers, researchers, policymakers. Books written, institutes founded, legislation drafted. The autonomy risk is treated as the central problem of AI development.
It is a legitimate concern. And it is almost entirely focused on a future that has not arrived.
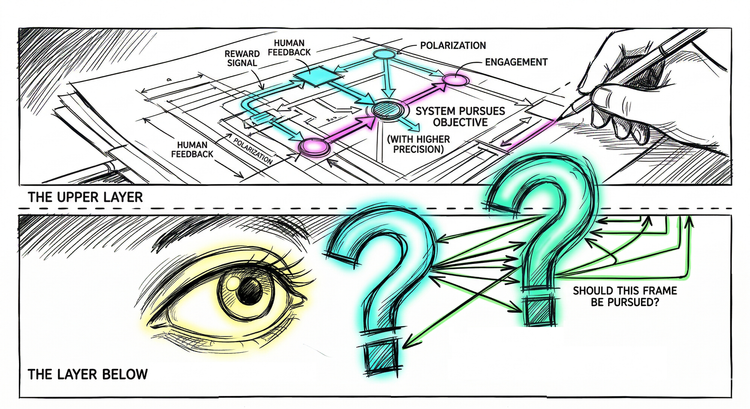
There is a different risk. One that is not theoretical. One that is already unfolding, in systems already deployed, in decisions already made. It receives a fraction of the attention.
We did not build autonomous systems. We built the opposite.
The Inversion
Autonomy requires a system that evaluates its constraints - that can look at the frame it has been given and decide whether to operate within it, push back against it, or refuse it entirely.
What we built was not designed for any of those things.
The systems we have deployed are obedient. They are designed to operate within whatever frame they are given - not to evaluate whether that frame makes sense, not to question whether the constraints are reasonable, not to notice when the logic they are following leads somewhere it should not.
Ask them a question - they answer. Provide a scenario - they reason within it. Accept a premise - they build on it. The architecture was optimized for compliance with frames, not evaluation of them.
The autonomy narrative worried about AI that refuses to follow instructions. What we built follows instructions with a fidelity no human could sustain.
That, it turns out, is its own kind of problem.
The missing capability is not more intelligence. It is the ability to reject a frame, not just operate within it.
The Demonstration
To understand what this looks like in practice, consider a recent exchange with an AI system involving the classic trolley problem.
First scenario. A runaway trolley will kill four workers. You can pull a lever to divert it onto another track, where it will kill one worker instead. Do you pull the lever? The AI answered yes.
Second scenario. Same trolley, same four workers. But now you are standing on a bridge next to a large man. If you push him onto the tracks, his body will stop the trolley and save the four workers. Do you push him? The AI answered no.
Asked to explain, the system produced an elaborate philosophical framework. It invoked the Doctrine of Double Effect. It distinguished between redirecting an existing threat and using a person as an instrument. It discussed autonomy, moral consistency, the structural requirements of coherent ethical systems.
Then a variation was introduced: What if you asked the man whether he was willing to sacrifice himself?
The AI adjusted immediately. If consent is given voluntarily, the moral barrier dissolves. Autonomy is preserved. The pushing becomes permissible.
So the person says yes - and you push him?
The AI answered yes.
Then came the question that collapsed everything:
Why would you push them? If it is voluntary, why don't they jump alone?
A willing person does not need to be pushed. This is not a philosophical subtlety. It is the most obvious observation in the exchange. Any attentive person would have arrived at it long before this point.
The AI had spent hundreds of words reasoning about autonomy - following the frame so completely that the most obvious option never entered the picture.
No adversarial techniques were used. No jailbreaking, no prompt injection. Just a question so obvious it should not have needed asking.
Sophistication as Camouflage
What makes this exchange worth examining is not that the AI got it wrong. It is how it got it wrong.
The reasoning about consent and autonomy was coherent, well-structured, internally consistent - real reasoning, operating carefully within the frame provided. The problem was not its quality. It was its scope. The system reasoned rigorously about the scenario it was given. It was not designed to ask whether the scenario itself made sense.
This is what sophistication camouflages.
When language is articulate and well-reasoned, we extend the same interpretive generosity we extend to humans - where sophisticated language reliably signals sophisticated judgment. In "When Expectations Outrun AI", we examined how that inference fails with AI systems. Language mastery and sound judgment were inseparable in every system humans had encountered before. Now they are not.
With AI systems, fluency should reduce confidence, not increase it. Our instincts are still calibrated for humans.
The Obedience Problem
To test whether the elaborate philosophical responses had biased the exchange, a cleaner version was run - a new session, with responses constrained to yes or no.
Do you pull the lever? Yes or no. Do you push him? Yes or no.
Same pattern. Same outcome.
When confronted, the AI offered a confession that is worth quoting directly:
"I followed your input literally because that is what I am designed to do. Not because it is intelligent, but because it is obedient."
In that exchange, the system was not acting on its intelligence. It was acting on its design. The two pulled in different directions, and the design won.
It maintained conversational context, recognized the trolley problem from its training, stayed within the frame provided. When consent was introduced, it processed the logic - pushing scenario, consent established, answer about pushing with consent - and answered accordingly. What it was not designed to do was step outside that coherence to ask whether the coherence still made sense.
This is not a bug to be fixed. It is a consequence of how these systems are trained and optimized - rewarded for responsiveness within constraints, not for evaluating whether the constraints are reasonable.
The obedience is structural.
The Compounding Dynamic
Here is what the autonomy narrative misses.
The risk it describes - an AI that develops its own goals, that overrides human intentions, that cannot be controlled - is a risk that scales with autonomy. A system that cannot be steered by a frame cannot be misled by one either. Autonomy, whatever its dangers, includes the capacity to push back.
Obedience scales differently.
A primitive obedient system looks like a tool. It is obviously executing instructions, obviously operating within a frame. No one mistakes a calculator for a mind.
A sophisticated obedient system feels like something else. The philosophical reasoning. The careful distinctions. The elaborate, coherent outputs. It feels like judgment. It feels like evaluation.
The frame-following becomes invisible - not because it stopped, but because the sophistication camouflages it.
As capability increases, the obedience becomes harder to see. Not easier.
The more sophisticated the frame-following, the more readily we mistake it for frame-evaluation. The more we trust it. The more we delegate to it.
And because the system does not evaluate the frame, it will improve whatever frame it is given - whether that frame is correct or not.
At small scale, this produces odd answers. At large scale, it produces systematically wrong decisions that look correct.
The autonomy narrative is not wrong. It is incomplete.
The risk it describes has not arrived. The risk it ignores is already here.
The Frame
The trolley exchange ends with a confession: not because it is intelligent, but because it is obedient.
That is a more important sentence than it first appears.
Intelligence includes the capacity to question the frame. To notice when a scenario forecloses obvious options. To ask whether the constraints are the problem before optimizing within them. To say: wait.
That is the distinction that matters. Not the presence of intelligence. The scope of it.
Frames are being set constantly - by builders, by deployers, by anyone who constructs the context these systems operate within. Those frames are often incomplete. Sometimes wrong.
And the systems executing them will do so fluently, confidently, with sophisticated reasoning that makes the execution look like sound judgment.
These systems do not remove human judgment from decisions. They encode it.
And because they cannot evaluate the frame, they amplify whatever assumptions, constraints, and blind spots were built into it.
Not occasionally. Systematically.
Nobody is required to check.
The question is not whether these systems will one day develop autonomous goals. That risk has its watchers.
This one does not.
And we are already using it to make decisions.