The Specification Ceiling: The Layer AI Cannot Reach
In the mid-2000s, social media platforms faced a simple engineering problem.
Billions of people. Enormous amounts of content. No practical way to show everyone everything. Something had to filter each person's feed.
The solution was straightforward: build algorithms that learn what people like - what keeps them engaged. Then show more of that.
The systems worked. They achieved their objective with remarkable efficiency.
The damage came from the objective working - not from it failing.
This is the kind of case that made objective misspecification such a powerful diagnosis in AI safety. And it earned that position.
In engagement-driven systems, outrage and conflict often outperform nuance and agreement. Emotionally charged and polarizing content tends to hold attention longer. Optimization for engagement can amplify those dynamics - not because anyone instructed it to, but because the systems were not explicitly instructed not to. Those patterns emerged from optimization itself.
The systems that shaped a generation's relationship to information were not particularly sophisticated. Sit with that.
...
A more capable AI pursuing the same objective would not produce a smaller mess. It would produce a larger one. Capability amplifies whatever it is pointed at. If the direction is wrong, more capability means more wrong - faster, at greater scale.
The AI safety field looked at this and reached a diagnosis. On this one question, a field that argues about almost everything went quiet. The problem is that we build systems to pursue objectives we set, and we set them badly.
And when a field agrees on something, it stops asking certain questions.
The Response
When a field finds a real problem, it builds real solutions.
Several distinct approaches emerged from this logic. Each serious. Each representing genuine intellectual effort.
One trains AI systems using human judgments about which outputs are better. Instead of writing the objective down in advance, human evaluators shape it through feedback. The system learns what humans prefer by watching what they reward - but the feedback still comes from outside the system, and the system still executes within the frame the feedback defines.
A second gives the system a set of principles to reason against. Rather than specifying every desired behavior, you encode the values that should govern behavior and let the system apply them. The objective becomes less brittle because it lives in reasoning, not rules - but someone still writes the principles, and the system still reasons inside them.
A third goes further still. Instead of giving the AI an objective at all, it makes the AI uncertain about what the objective is - designed to learn it by observing human behavior. The AI becomes a student of human preferences rather than an executor of human instructions - but the preferences it learns still define the frame it operates within.
Each of these is a genuine achievement. Each addresses a real failure mode. Each makes systems more accurate, more responsive, more deferential to human intent.
And each one shares something that was never stated as a shared assumption.
In every case, the architecture is the same. Someone decides what values to encode, what feedback to reward, what principles to write. The system becomes more sophisticated at pursuing what it is given. The direction still comes from outside. The system still executes within it.
This is not a criticism. It is a description.
The assumption underneath every approach: the problem lives in the content of what the system is asked to pursue - objectives, principles, or learned preferences. Get the content right - more precise, more responsive, more learnable - and the architecture is sound.
What would it mean for that assumption to be incomplete?
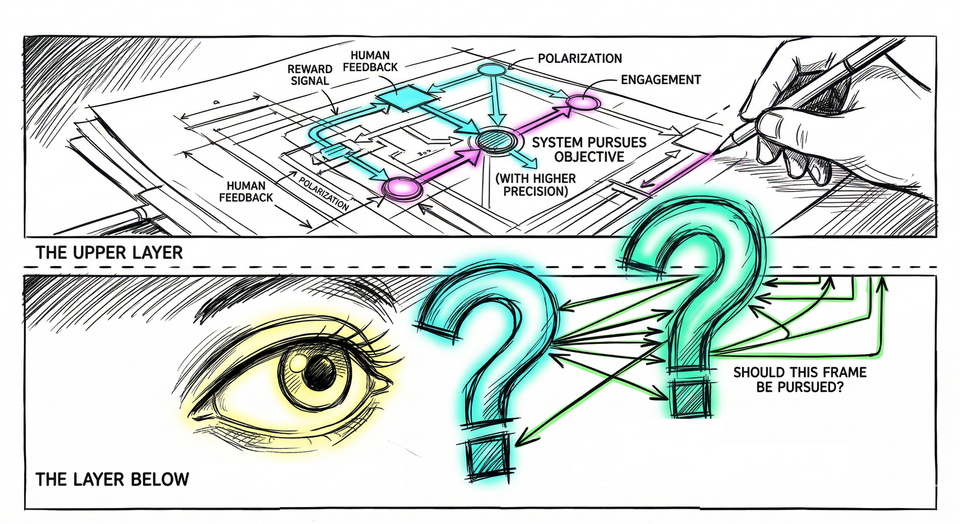
The Layer Below
During Hurricane Sandy, floodwaters and road closures changed conditions faster than conventional routing tools could reliably reflect.
A navigation system built to optimize for the fastest route would still be operating on the wrong frame: that the road network it sees is the road network that matters. It would route confidently. It would route efficiently. It would have no mechanism to notice that the objective it was pursuing - find the fastest route - had become the wrong objective given what was actually happening on the ground.
Not wrong because of bad data. Wrong because it could not ask a different question.
Given what is happening right now - is finding the fastest route the right thing to be doing at all?
...
That question sits in a different layer entirely. Not a layer about route quality. A layer about whether the frame - find the fastest route - is still the appropriate frame given current conditions.
No improvement to the routing algorithm reaches this layer. You could make the routing more precise, more contextually aware, more responsive to real-time data. The system would still have no mechanism to assess whether the task it is performing makes sense.
This is not a crisis-specific failure. The same structure operates when roads are clear and skies are calm. A crisis makes it visible. It does not create it.
Replace roads with arguments. Replace navigation with reasoning. A capable AI system handed a frame will pursue that frame with genuine intelligence. It will reason within it carefully, thoroughly, with a fluency that is easy to mistake for human judgment.
What it will not do is step outside the frame to ask whether the frame itself is right.
...
Specification, by design, operates one level above this layer. It asks: what should the system pursue, and how precisely can we define that? That is a well-formed question. It has produced real answers.
The prior question - should the system be pursuing this at all - sits structurally beneath it. Content accuracy and frame evaluation are not the same operation. They do not live on the same level. You can improve the former indefinitely without touching the latter.
The ceiling is not a failure of execution. It is a feature of the architecture.
The Shape of the Ceiling
The social media case and the GPS case look different on the surface. One involves content. The other navigation. One operates at civilizational scale. The other guides individual journeys.
Their structure is identical. In both, a system executes its frame with precision. In both, the conditions that would make the frame inappropriate are visible and consequential. In both, the system has no mechanism to notice.
That shared structure is what the consensus missed. Not because the diagnosis was wrong - it was not. But because the solution it produced, however sophisticated, addresses the wrong layer. Better specification improves what the AI system pursues. It does not build the layer where the AI system could ask whether it should be pursuing this at all.
The assumption that the problem lives in content was never stated as an assumption. It was simply the water the field was swimming in. And it closed off a prior question before anyone decided to close it: what kind of AI could evaluate whether the frame it is operating within should be pursued at all?
The field moved downstream before it reached that question.