When Expectations Outrun AI
You know LLMs are not human. Everyone knows this. Yet when we talk or build with an LLM, our brain easily slips.
Not because we are careless. Because of how human cognition works.
You ask for a plan. The language is articulate, well-structured. It lays out milestones, dependencies, risk mitigation. Sounds like someone thinking through the problem. Your brain registers: intelligence.
For all of human history, this inference was reliable. Language mastery meant human intelligence. If something spoke with such articulation and structure about complex topics - it understood them - with all the cognitive machinery behind it. Language and understanding were inseparable.
Then we built machines that master language.
They speak about anything articulately. Sound thoughtful, knowledgeable, wise. Every conversational cue that usually signals human-like intelligence is present.
Then you return tomorrow. The plan is gone. Not refined, not remembered, not built upon. Gone. The conversation starts from zero.
This happens constantly. Eloquence and reasoning with no follow-through. Perfect plans that vanish.
Sometimes: perfect explanations are followed by obvious misses or confident fabrications wrapped as facts (hallucinations).
Each time, there is a moment of cognitive dissonance. Wait, if you understood that, why did you not...?
You are surprised. Why?
Here is the trap: you cannot turn off your inference.
When something speaks fluently about complex topics, your brain does what it evolved to do. It infers intelligence with the whole cognitive architecture behind it - understanding, continuity, goals, grounding - everything human intelligence includes.
LLM intelligence is real. But the architecture behind it is fundamentally different. We keep expecting the human-like package because sophisticated language makes it sound human.
Why Engineering Never Stops
Models get better. Each version more capable - better articulation, more knowledge, better reasoning, better synthesis...
Better capability creates stronger expectations.
If it discusses strategy this well, surely it can maintain direction. If it explains debugging this clearly, surely it can catch bugs. If it reasons about goals, surely it can pursue them.
The hype amplifies this. Marketing promises superhuman intelligence. Demos show impressive capability.
Better capability + stronger hype → even stronger expectations.
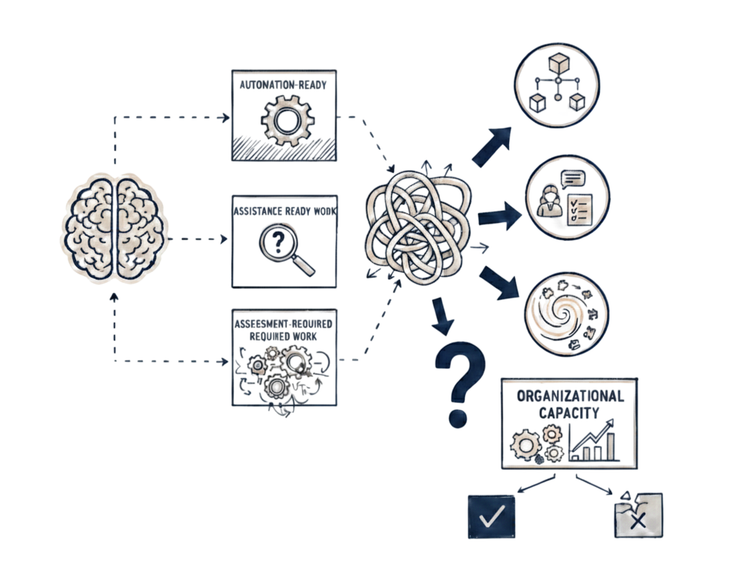
As a result, many rush to apply LLMs everywhere - customer support, code generation, clinical triage, strategy planning...
Then reality. The customer support agent cannot track context across conversations. The code generator cannot maintain coherence across a codebase. The strategic advisor cannot remember what mattered yesterday.
The intelligence is there. The architecture has constraints.
So we engineer.
First, compensating for architectural constraints - prompt engineering, context management, RAG systems, output validation, retraining pipelines...
Second, compensating for overapplication - human-in-the-loop, safety guardrails, fallback mechanisms, audit and compliance, cost controls...
With enough engineering, the gaps are bridged. But look at what it took. Two separate engineering efforts, both massive.
This is the paradox. Better models should reduce engineering - not increase it.
The cycle becomes clear:
Better models + stronger hype → stronger expectations → wider application → more places where architectural constraints matter → more engineering to compensate.
The Architecture
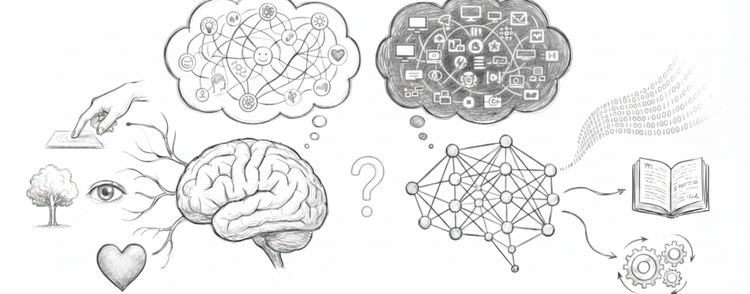
LLMs learn from massive datasets - trillions of tokens from text across the internet. They build internal representations, abstract models compressed from all that data.
But here is what matters: these representations are frozen after training, any adaptation happens only within the context window, are learned from descriptions rather than lived experience, and the model maintains no goals beyond the immediate response.
Four architectural constraints hidden by fluent language.