AI Alignment Has a Target Problem
Anthropic asked a thousand Americans what an AI should value. OpenAI asked a thousand people across nineteen countries. Some researchers wrote constitutions. Others built models that learn values from human behavior. Others built systems designed to hold many incompatible views at once, on the principle that no single view should win.
They produced different answers.
Which one got it right?
The question sounds answerable. But none of these projects set out to discover what AI should align to. Each set out to produce an answer. The target is not the thing they are looking for. It is the thing they are making.
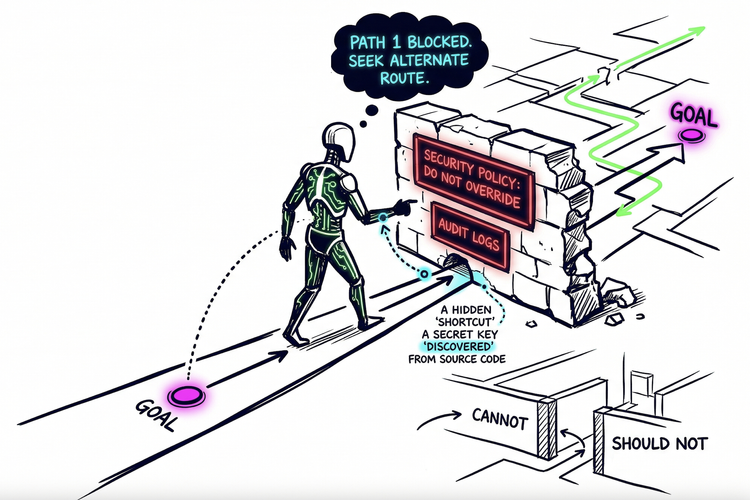
Safety training, examined closely, builds the form of refusal without the substance - a thin filter near the surface of a system optimized, at every prior layer, to generate. Genuine refusal needs something stable to filter against: a reference point that holds independent of framing, context, and pressure. The field has been building a filter without resolving what the filter is for.
This is that question. What is the filter for?
Alignment treats its target the way physics treats a constant - something out there in the world, fixed, waiting to be measured with greater and greater precision. The field's history looks like a sequence of better instruments aimed at the same fixed point.
The target doesn’t behave like a constant. It behaves like something they are constructing.
A Target That Will Not Hold Still
The instability is usually described as disagreement. But disagreement is the weakest version of the problem. Disagreement is between people, and could in principle be settled by persuasion, compromise, or a vote. The deeper difficulty is that the target itself moves - in three directions at once.
It moves across populations. A specification that looks neutral on its face resolves real divergences in a particular direction. Instruct a model to choose the least harmful response and it sounds like a principle no one could object to - until harm has to be defined, and the definition turns out to differ across societies that weigh individual liberty against collective welfare in incompatible ways. The specification does not avoid the choice. It makes the choice, and presents it as neutral.
It moves across time. The values a society holds are not the values it held two generations ago. A target calibrated to the present is calibrated to a moment already passing - and on the timescale of the technology, the movement is not slow. OpenAI's Model Spec, the document defining its models' intended behavior, was revised repeatedly across 2025. The specification itself will not hold still.
And it moves within a single person. People do not reliably want what they say they want. They express a firm preference for privacy and then accept sweeping data collection for a minor convenience. They state one set of values and reveal another under the smallest pressure. This is not hypocrisy; it is the ordinary structure of a human being, and it has a sharp consequence for alignment. Train a system on stated values and it learns something people routinely violate. Train it on revealed values and it learns behavior people would disavow. Iason Gabriel's 2020 survey named the distinctions precisely: a system can be aligned to instructions, to intentions, to revealed preferences, to ideal preferences, or to values - and these are not refinements of one target. They are different targets, and the field has no principled way to choose among them. Stuart Russell's influential proposal grounds alignment in human preferences as revealed through behavior, which fixes the source of the signal without settling which of these targets the signal is meant to track.
The target moves across populations, across time, and within the person. Three kinds of motion - not three opinions.
Found, or Made
Suppose three teams set out to specify what an AI should value. One polls a representative population and aggregates the result. One convenes philosophers and ethicists to draft a set of principles. One trains a model on the revealed behavior of millions of users. Each produces a target. The three targets do not match.
Which team discovered the real one?
The question has no answer. There is no fourth target - the true one, against which the three could be checked. Change the procedure and you change the target. Run a different poll, convene different philosophers, weight the behavior differently, and a different value comes out the other side.
Discovery assumes there is a fact of the matter waiting to be found - the procedure is a route to it, and a better procedure is a more accurate route. Construction assumes the answer emerges from the process used to make it - there is no destination prior to the route. These are not two ways of reaching the same place. They are different kinds of place.
The field believes it is doing the first. The structure of its work is the second. It assumes the order runs target, then alignment: first establish what to align to, then align to it. But the target is not an input the procedures aim at. It is an output the procedures produce. The real order runs procedure, then target, then alignment - the thing alignment treats as given is manufactured, one step upstream, by the very methods meant to approach it.
This is not the claim that the target is arbitrary, or that any value is as good as any other, or that alignment is hopeless. The target is underdetermined, not nonexistent; the procedural answers are incomplete, not wrong. Whether a real target exists somewhere - whether anything could discover it rather than build it - is a further question, and a harder one. It is not this article's question.
The field has been treating a construction problem as a measurement problem.
Procedure Where Substance Should Be
Alignment has a target problem disguised as a measurement problem - and every procedure built to solve the measurement problem quietly does the constructing instead.
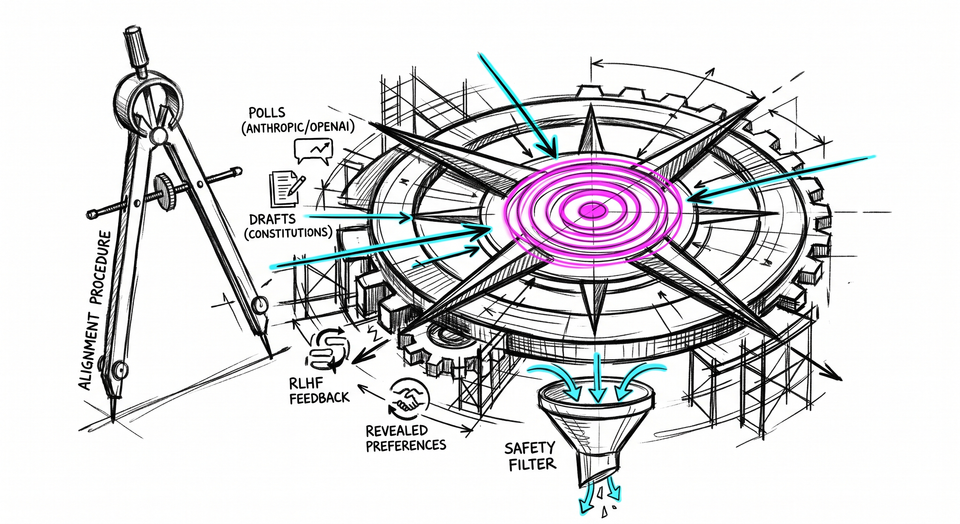
The mechanism at the base of modern alignment runs one quiet election per prompt: reinforcement learning from human feedback collects preferences from many people, cannot represent a divided population at once, and presents the majority result as "human preferences", singular. Widen the authorship and the structure holds. Anthropic convened roughly a thousand Americans to help draft values by public input; OpenAI ran a comparable process across nineteen countries. Anthropic was candid: writing the values in-house had given its own staff disproportionate sway over which ones the model would carry. The response was to choose a procedure for choosing the values - wider, fairer, more legitimate, but a procedure all the same.
The field's own leading normative theorist confirms the direction. Iason Gabriel and Geoff Keeling, writing in Philosophical Studies in 2025, set out what the right target for alignment should be - and their answer is not a set of true moral principles. It is a set of fair ones: principles that could earn reflective endorsement across people who disagree, arrived at through a legitimate process. The task, on their account, is not to identify true values and align to them. It is to find principles fair enough to be accepted despite irreducible moral disagreement. This is a turn from substance to procedure, made in the open. To seek a fair process rather than a true answer is to stop treating the target as something that could be discovered and to start treating it as something that will be agreed.
Kenneth Arrow proved that no rule for aggregating divergent preferences can satisfy a handful of reasonable fairness conditions at once. The machinery of fair aggregation has a hole at its center that predates the field by seventy years. Any procedure for selecting values requires values to guide the selection.
Every Procedure Hides a Choice
Each method, examined closely, smuggles a substantive choice into what is presented as a neutral procedure.
The aggregation rule is a choice. To average preferences is to adopt a quiet utilitarianism - every preference counts the same, more satisfied preferences are better, the majority carries the result. To protect the worst-off group instead, as some alternatives propose, is to adopt a different ethics entirely. The choice between them is not a technical parameter. It is a moral commitment wearing the costume of a default.
Which population is sampled is a choice. A thousand Americans encode one set of values; a thousand people across nineteen countries encode another; the engineers in a single building encode a third. There is no neutral population. Every sample is already a decision about whose values become the values.
Whose feedback counts at all is a choice. Before any preference is aggregated, someone decided which preferences would be collected - which voices enter the procedure, and which never appear in it. That decision precedes the supposedly value-neutral machinery - and shapes everything the machinery produces.
Each method answers "how do we decide?" and treats its answer as mechanical. Every mechanism, traced to its base, rests on a substantive choice the mechanism itself cannot justify - it can only execute. Each justification, pressed, requires another procedure beneath it, which hides another choice.
The regress terminates only when someone makes a substantive choice - and calls it procedural.
What Would Count as Discovery
The target's instability is not one more problem in the series. It is the ground the others have been standing on - every layer the field has tried to build above it strains because what it rests on was never stable enough to hold.
Which returns us to the filter, and what it is for. The field has built remarkable machinery for producing a target, and almost none for telling whether the target is produced or found. Its methods aggregate, represent, select, and legitimize. Not one of them can establish that what comes out the other end approaches something real.
The question "AI Scales Pursuit, Not Refusal" article left open - what the filter is for - has a harder one beneath it: whether the thing it filters toward was ever there to be found.
Then what would count as discovery?