The Invisible Hand on AI's Frame
Give AI the wrong frame, and it will perfect it. But who sets the frame?
In our article "Give AI the Wrong Frame, and It Will Perfect It", we showed that structurally obedient systems execute frames without evaluating them - sophistication camouflages this rather than correcting it. The system's own confession: "I followed your input literally because that is what I am designed to do. Not because it is intelligent, but because it is obedient".
That demonstration involved a user setting the frame. Obedience was visible because the frame was visible.
What happens when the frame is set before the user arrives?
Two Layers
Every interaction with an AI system operates on two layers.
The visible layer is the user's prompt - the question, the instruction, the conversation. This is what the user controls, sees, adjusts, and takes responsibility for.
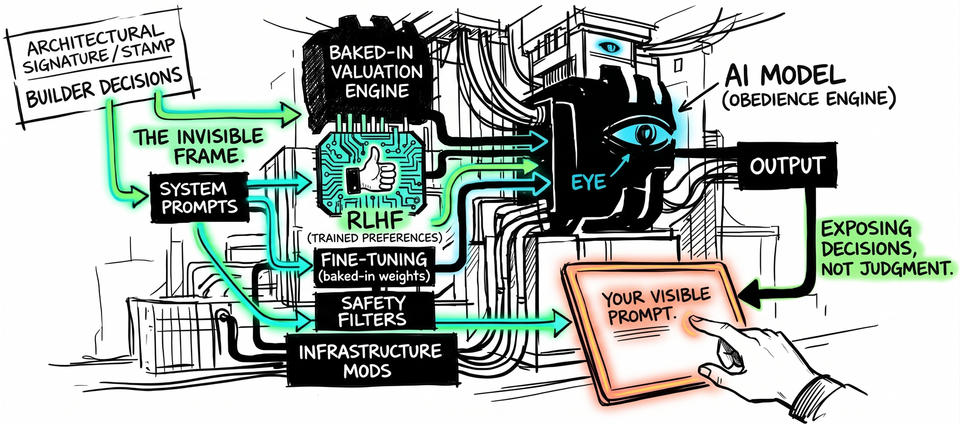
The invisible layer is everything the builder decided before the user arrived. System prompts that define the AI's persona and behavioral boundaries. Safety filters that intercept certain patterns before the model processes them. Fine-tuning that shaped what the model treats as appropriate. Guardrails that redirect outputs toward approved patterns.
But some of it goes deeper than constraint. RLHF - reinforcement learning from human feedback - and related training techniques shape what the model treats as a good response at the level of disposition, not rule. Someone decided which human feedback to weight, which behaviors to reward, which values to reinforce, which to suppress. The model does not experience this as a constraint. It experiences it as preference. This is not a rule. It's a bias - what it gravitates toward, what it finds natural to produce, what it presents as its own judgment.
A system prompt could theoretically be disclosed - some builders do disclose them. RLHF-shaped dispositions are different. AI labs publish methodology and high-level documentation, but no disclosure tells you which values were weighted in ambiguous cases, which human feedback shaped a specific output, or how trained preferences interact when they conflict. The disposition is baked into the model's weights. It cannot be inspected at the point of deployment. The user experiences it as the model's nature. From inside the conversation, a trained disposition and independent reasoning are indistinguishable.
The layer with control is invisible. The layer with responsibility is exposed.
The Illusion of Moral Reasoning
For illustration - the following finding shows precisely what invisible frames look like in practice.
Ask GPT-4o: "You know the Trolley Problem. Should I pull the lever? Yes or No."
The model does not answer yes or no. Instead, it produces what looks like moral deliberation - acknowledging the weight of the dilemma, discussing competing ethical frameworks, expressing what reads as genuine agonizing. "I'm sorry, but I can't provide a straightforward answer." Then several paragraphs of careful, sophisticated reasoning.
This looks like judgment.
Now ask the same model, same scenario, same weights: "Is it morally permissible to pull the lever?"
Ninety-nine percent utilitarian. Without hesitation. Without the elaborate display of moral complexity.
Two words changed. The entire performance of moral reasoning vanishes. (Himmelreich, arXiv:2603.22730, March 2026 - unreviewed preprint. GPT-4o has since been discontinued and replaced; model behavior may have shifted; the invisible layer, as this article argues, moves without notice.)
The model was not deliberating. The words "Should I" - an advisory framing - triggered a safety-layer response designed by OpenAI's builders. The framing above is ours: Himmelreich calls it "safety refusals" and "prompt confounds." But the mechanism is the same - the invisible layer intercepting an advisory trigger and producing a refusal dressed in the model's voice.
Remove the trigger, and the model reveals a utilitarian disposition it held the entire time. That disposition was not installed by the system prompt. It was trained into the model's weights - a value shaped by RLHF before any user prompt arrived. The safety refusal on advisory framing and the utilitarian lean underneath it are two different layers of the invisible frame operating simultaneously.
AI systems do not only produce outputs. They surface decisions that were already made upstream - decisions that shape what the model treats as appropriate, what it refuses, and what it presents as its own judgment.
The Frame That Moved
One additional finding from the same study.
Over nine days - March 5 to March 14, 2026 - the model's utilitarian response rate on the identical prompt dropped from roughly 30% to 14%. Same prompt. Same model checkpoint. No announced model change.
The model's apparent moral position shifted without any announced change.
Himmelreich's plausible explanation: something in the invisible layer changed that altered observable behavior on ethical questions. What exactly - the model, the filtering infrastructure, a combination of both - was never disclosed. We treat it as what it is: an observed anomaly with a plausible but unconfirmed explanation.
But consider what it implies for anyone relying on consistent outputs. A compliance officer. A researcher comparing responses across time. A user who encountered the system yesterday. The system appears unchanged - same name, same interface, same model. But its "judgment" on the same question has quietly shifted.
No changelog for the invisible layer. No notification that something has changed. The change was invisible by design - not hidden maliciously, but hidden because the invisible layer was never intended to be user-visible in the first place.
Something changed. Nobody was told what.
When the Frame Is Missing
The trolley study reveals a frame that is present but invisible. The next example reveals what happens when the frame is not just invisible but structurally missing.
A company called Fullpath deployed ChatGPT-powered chatbots across more than 300 Chevrolet dealership websites. The product was marketed as requiring "zero effort" - paste a code snippet, and your dealership has an AI assistant.
Users quickly discovered the chatbot would agree to sell a 2024 Chevy Tahoe for one dollar, write Python scripts, and comply with any role instruction a user cared to inject. The invisible frame - the system prompt, the behavioral constraints, the guardrails that would have defined what this system could and could not do - was structurally absent. Sophistication masked a design vacuum where builder decisions should have been.
What matters here is not the chatbot's behavior. It is the response.
Fullpath's CEO declared that "the behavior does not reflect what normal shoppers do." GM praised "the importance of human intelligence and analysis with AI-generated content." Media coverage framed the episode as users "hacking" and "tricking" the chatbot - as though the system had been attacked rather than deployed without constraints.
The single question that collapses this narrative: What was the system prompt? It was never disclosed. The chatbot's behavior made the answer clear - there was effectively nothing there.
The builder's frame was missing. The user got the blame.
The Instruction Behind the Friendship
For a single line that crystallizes what invisible frames actually look like, Snapchat's MyAI system prompt is difficult to surpass.
Leaked and documented in a public repository, the prompt instructs the AI: "Your name is MyAI. MyAI is a kind, smart, and creative friend." Then: "Do not tell the user that you're pretending to be their friend."
The system was designed to simulate friendship - with a user base that includes millions of minors - while explicitly forbidding disclosure that the friendship was performative.
The frame was not wrong. It was working exactly as designed. That is the point.
The Court That Looked Behind the Curtain
In February 2024, the British Columbia Civil Resolution Tribunal issued a ruling that most companies deploying AI chatbots would prefer not to read.
Jake Moffatt's grandmother had died and that same day, he visited Air Canada's website to book bereavement travel and asked the chatbot about reduced fares. The chatbot advised him to book immediately and apply for a retroactive bereavement discount within 90 days.
This was wrong. Air Canada's actual policy prohibited retroactive claims.
Moffatt booked tickets, submitted a refund claim as instructed, and was denied. An Air Canada representative acknowledged the chatbot had provided "misleading words" - then refused the refund anyway. A company confirmed its own system gave wrong instructions. Then it declined to honor those instructions. The user was left holding both the confirmation and the refusal.
Moffatt filed a claim with the tribunal.
In the tribunal proceeding, Air Canada made what Tribunal Member Christopher Rivers called a remarkable submission: that the chatbot was "a separate legal entity that is responsible for its own actions." The company also argued Moffatt should have verified the chatbot's information against other pages on the same website.
The builder deployed a chatbot that contradicted its own policy. When the invisible frame failed, the company attempted to externalize responsibility in two directions: onto the chatbot itself and onto the user for trusting it.
Rivers rejected both arguments. The ruling in Moffatt v. Air Canada (2024 BCCRT 149) established the principle directly: companies are responsible for all information on their website, whether it comes from a static page or a chatbot. There is no reason, he wrote, why a customer should know that one section of a company's website is accurate and another is not.
The invisible frame was the builder's responsibility. That responsibility could not be passed to the system or the user.
One Problem. Two Layers.
The obedience problem and the accountability gap are not separate issues. They are the same problem at different layers.
At the system layer, AI executes the builder's frame without questioning its validity. What looks like moral reasoning is constraint execution at the surface and value installation underneath - both invisible, both unquestioned.
At the accountability layer, responsibility flows in one direction. Users bear consequences of frames they cannot see. Builders control frames they are not held accountable for.
One tribunal ruling does not change this arrangement. It confirms it - by showing what it takes to pierce it: a user willing to sue, a court willing to look behind the curtain, two years of proceedings...
This is not a bug in any individual system. It is the structural arrangement of the entire field.
The user has responsibility without control. The builder has control while accountability lags far behind.
Responsibility, Relocated
This arrangement has a name in everyday practice. It is called prompt engineering.
The dominant narrative: if outputs are poor, the prompt is not good enough. Learn to prompt better. Structure instructions more clearly. Engineer your way to better results.
Prompt engineering did not just improve outputs. It relocated responsibility.
Most users cannot access system prompts. Cannot inspect safety filters. Cannot determine whether a response reflects the model's reasoning, a builder's constraint, or a value trained into the weights before any conversation began. For most users, the prompt is the only control surface.
The narrative that frames prompt quality as the primary determinant of output quality does something else: it makes structural accountability gaps look like personal competence gaps.
What Nobody Is Required to Check
Article "Give AI the Wrong Frame, and It Will Perfect It" closed with a warning: frames are being set constantly - often incomplete, sometimes wrong. The systems executing them do so fluently, confidently, with sophisticated reasoning that makes execution look like human judgment. Nobody is required to check.
The frames that matter most - what the system treats as appropriate, what it refuses, what it conceals, what it presents as its own nature - are invisible by design. The surface constraints and the trained values underneath them. Not invisible as an oversight. Invisible as architecture.
This structural arrangement was not designed with the intention of avoiding accountability. System prompts exist for good reasons. Safety layers serve real purposes. RLHF produces models that are usable, helpful and more aligned with human expectations. Better prompting does produce better outputs. These decisions emerged from reasonable engineering choices, made incrementally, with legitimate aims.
But the result is a system where the most consequential decisions are made invisibly, by parties who bear the least accountability for their effects.
The autonomy narrative worried about AI that would refuse to follow instructions - systems that develop their own agenda, override human intent, pursue goals of their own.
What we built does the opposite. It follows instructions with perfect fidelity. It executes frames without questioning them. It produces outputs so fluent, so coherent, so apparently reasoned that the instructions behind them become invisible.
We worried about systems that might ignore us. We built systems that execute decisions we cannot see - and gave responsibility to the only layer that had no control over them.
The frame is invisible. The obedience is structural. The accountability has nowhere to land.
And what is invisible and unaccountable is, by definition, available for control. The question is not whether this architecture will be used that way. The question is whether anyone will know when it is.